Lesson 1 · mission: understand the GPU execution model · the diagram, re-drawn for Triton
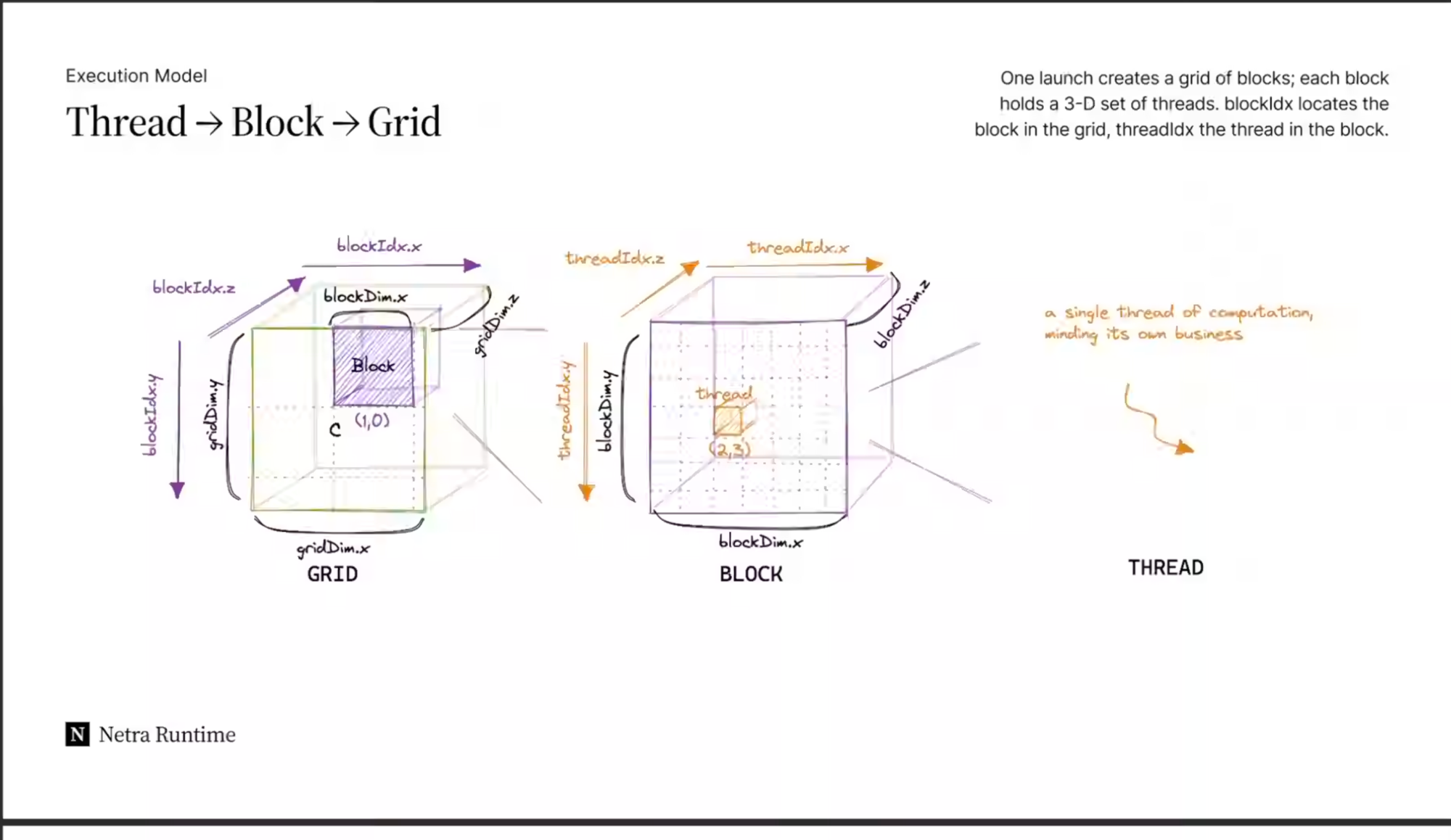
The diagram you shared is the CUDA execution model: three nested levels —
a GRID of BLOCKS, each block a 3-D set of
THREADS. CUDA asks you to write code from the point of view of
one single thread, which figures out which data element it owns using
blockIdx and threadIdx.
Triton keeps the grid and the block. It deletes the thread from your code. You write one program that owns a whole block of data at once. That is the entire idea of this lesson — everything below is detail.
| Level | In the diagram | What it is |
|---|---|---|
| GRID | the big outer cube, gridDim.{x,y,z} | All the work for one kernel launch. |
| BLOCK | the small purple cube at (1,0), blockDim.{x,y,z} | A group of threads that can share fast memory and synchronize. |
| THREAD | the tiny orange cell at (2,3) | "A single thread of computation, minding its own business" — processes one scalar. |
i = blockIdx.x*blockDim.x + threadIdx.x.__syncthreads(), coalescing, vectorization — by hand.tl.program_id(0).OpenAI's own words: Triton revisits the SPMD model and proposes "a variant in which
programs — rather than threads — are blocked." Kernels are "launched concurrently with
different program_id's on a grid of so-called instances."
(Introducing Triton, OpenAI)
| CUDA (the diagram) | Triton | Note |
|---|---|---|
blockIdx.x | tl.program_id(axis=0) | Which block/program am I? (Literally reads blockIdx.x in the compiled PTX.) |
gridDim.x | the launch grid tuple | How many programs were launched. |
blockDim.x | BLOCK_SIZE (a tl.constexpr) | How many elements one program owns — set by you, tuned by autotuner. |
threadIdx.x | — none — | There is no thread index in Triton. The compiler owns the threads. |
Vector add: output = x + y. Watch how every line is about the block, never a thread.
@triton.jit
def add_kernel(x_ptr, y_ptr, output_ptr, n_elements,
BLOCK_SIZE: tl.constexpr):
pid = tl.program_id(axis=0) # which block am I? (≈ blockIdx.x)
block_start = pid * BLOCK_SIZE # first element MY block owns
offsets = block_start + tl.arange(0, BLOCK_SIZE) # a whole TILE of indices
mask = offsets < n_elements # guard the ragged last block
x = tl.load(x_ptr + offsets, mask=mask) # load the tile
y = tl.load(y_ptr + offsets, mask=mask)
output = x + y # one op over the WHOLE tile
tl.store(output_ptr + offsets, output, mask=mask) # store the tileSource (official tutorial): Triton · Vector Addition↗
# launch: how many programs (blocks) do we need?
grid = lambda meta: (triton.cdiv(n_elements, meta['BLOCK_SIZE']),)
add_kernel[grid](x, y, output, n_elements, BLOCK_SIZE=1024)The tells that you're at the block level, not the thread level:
tl.arange(0, BLOCK_SIZE) — you build an array of offsets, not a single index.output = x + y — one line adds 1024 elements at once. In CUDA this would be one scalar add, run by 1024 separate threads.mask — because a program owns a fixed-size tile, the last (ragged) block masks off the overflow. This is the price of thinking in tiles."But surely the threads still exist?" Yes — on the hardware.tl.program_id(0)compiles down toblockIdx.x, and the tile becomes many threads. The point is they're absent from your source code: the compiler does coalescing, thread swizzling, shared-memory allocation/synchronization, vectorization and tensor-core scheduling for you. (Triton docs)
blockIdx+threadIdx.
Triton = write code for one program instance that grabs a whole tile via tl.program_id;
there is no threadIdx, and the compiler manages the threads.
Read Introducing Triton (OpenAI) — ~10 min. Stop at the line about "programs — rather than threads — are blocked"; that one sentence is this whole lesson.
💬 I'm your teacher for this — ask me followups any time. Confused about why a "program" becomes "threads" on the GPU, or what a tile really is? Ask, and I'll build the next lesson around it.
Lesson 1 · Zain's AI Inference Lab · mission: understand the GPU execution model via Triton